票务系统性能优化

正式环境3台控制节点(4核8G)3台工作节点(8核16G),K8s群集实现高可用部署方式。
压测结果
单trip(4核3G(jvm 1.8G))服务
单热点数据下单接口:16qps
下单(20产品30天范围)支付接口:40qps(20qps+20qps)
产品查询接口:180qps
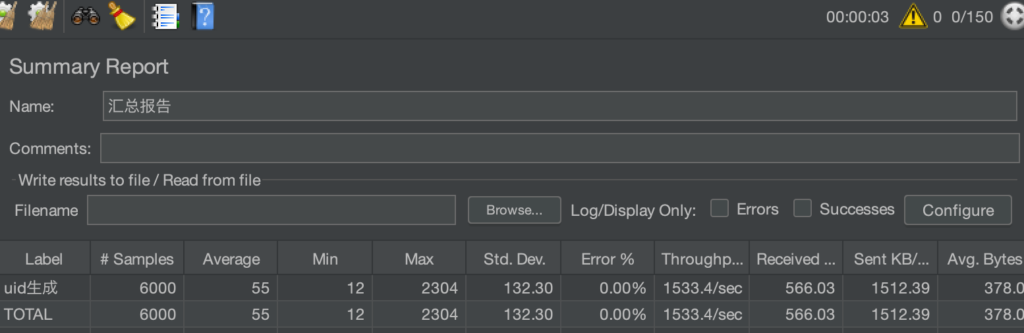
空接口(uid生成):600qps
双trip服务
单热点数据下单接口:16qps
下单(20产品30天范围)支付接口:76qps(38qps+38qps)
产品查询接口:220qps
空接口(uid生成):600qps
三trip服务
单热点数据下单接口:16qps
下单(20产品30天范围)支付接口:86qps(43qps+43qps)
产品查询接口:260qps
空接口(uid生成):600qps
PS: Gateway由spring cloud gateway改为 Higress 后空接口提升到1500~2000qps左右,其他接口变化不大,整体上有微微提升。稳定性有一定提升




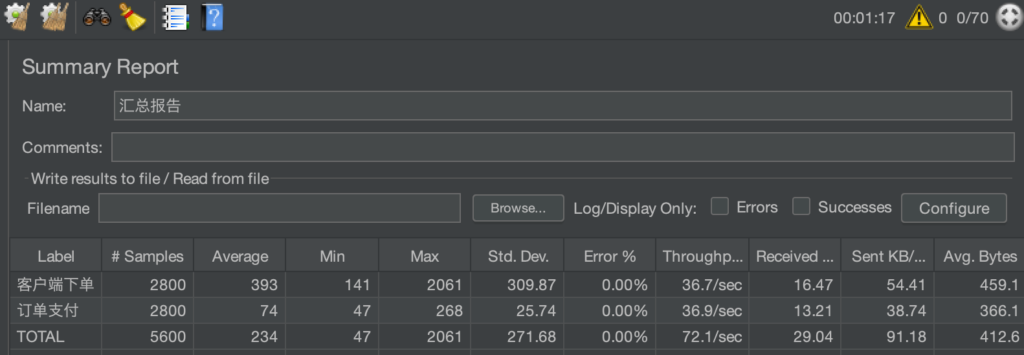
Higress网关压测空接口结果
已解决的问题
问题:接口响应不稳定,500ms~2s
修复:日志切面优化,IPUtil请求第三方http接口获取ip所属地转异步操作
问题:雪花ID workerId重复问题
修复:使用Redis发放 workerId
说明:Hutool提供的工具有小机率重复,不过在pod里重复机率大大增加,因为java进程ID固定为1
问题:pod时钟漂移,雪花ID生成异常
修复:出现飘移时强制时间戳+1
说明:目前雪花ID生成只需要有效不重复ID,不在意它对应的时间信息
问题:seata高可用部署多台实例时高并发下可能出现同时调用comfirm和cancel
修复:配置seataServer.properties中的二阶段重试时间由 1s 调整为 20s
说明:可能高并发的高频重试下引发的异常,调整后未再复现,不过并发量达到一定量时有复现的可能
问题:seata高并发下小机率报错io.seata.common.exception.FrameworkException: TCC branch Register error, xid:
修复:seataServer.properties 中添加 server.enableParallelRequestHandle=false
说明:此问题会引起大量线程长时间被占用,导致并发能力下降,而且效果非常明显
关闭前下单接口请求:300ms ~ 1.5s, 100线程并发压测:46ms ~ 30s(有时60s)
关闭后下单接口请求:100ms ~ 500ms, 100线程并发压测:158ms ~ 2s
问题:双trip下单无法跑满cpu
修复:jvm声明可用核心数 -XX:ActiveProcessorCount=4
说明:容器误以为可用核心为8核(主机核心数),创建了1000多个线程,线程切换浪费太多资源,声明后只创建400左右线程,且双trip下单能跑满4核
总结
下单接口由1.5s~3秒优化至400ms左右,100线程并发基本能保持较好的一个响应速度,在800ms左右,70线程400ms左右 gateway 对服务业务的并发影响不大,只对空接口并发影响比较大,qps一旦过千就需要优化,或者换成 Higress 作为网关。其实我本地(电脑16核)idea测试空接口直接trip访问的请求是5000qps,网关只有1000不到,排查到的问题是在网关的黑名单功能上,黑名单存放在redis,但是网关的redis客户端连接数一直为1,不会增加,关闭黑名单功能后qps增长至3000qps。但是正式环境关闭黑名单还是600多qps,也可能与分配的性能有关,网关被限制cpu为1核 目前的各资源已优化至双trip(4核)可跑满,基本上双trip服务能提供性价比最高的服务能力,三trip服务只能提升10%左右的并发量,但是能极大缓解trip服务业务处理压力,4台trip没太大意义,除非有大量后台处理业务,并且需要先检查提升其它中间件网关等组件的并发能力,再加4台,以提升接口并发响应能力 另外目前跑3台资源基本已满载,4台需要增加工作节点
优化点小记
JVM优化
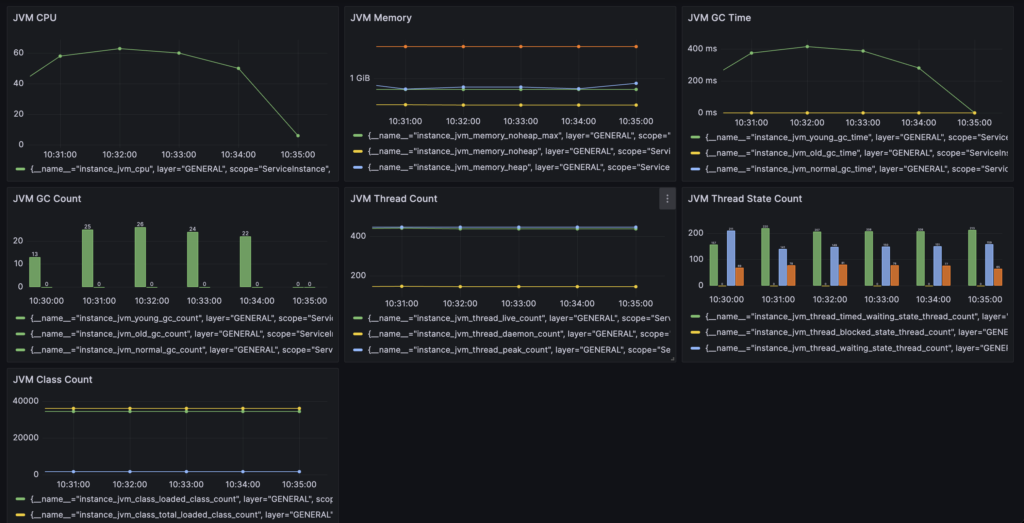
1.trip服务测试环境配置-Xms1g -Xmx2g,运行时pod内存占用在1.5G左右,以此为参考正式环境配置-Xms1824M -Xmx1824M,在预留一部分空间的情况下,固定堆内存大小为1824M,避免扩缩容对程序造成影响,保证服务的稳定性 2.-XX:ActiveProcessorCount=4 指定JVM可用核心数,避免容器误以为可用核心为8核(主机核心数),创建了1000多个线程,线程切换频繁造成资源浪费 配置: -Xms1824M -Xmx1824M -XX:MaxMetaspaceSize=256M -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:InitiatingHeapOccupancyPercent=45 -XX:+ParallelRefProcEnabled -XX:+AlwaysPreTouch -XX:+UseContainerSupport -XX:ActiveProcessorCount=4 -XX:MaxRAMPercentage=70.0 cpu 80%时 一分钟gc次数60次左右,总花费时间600ms~1s,平均每次16ms左右 cpu 60%时 一分钟gc次数30次左右,总花费时间400ms左右,平均每次13ms左右
skywalking采集JVM信息
Seata配置优化(seataServer.properties)
1.二阶段重试时间配置
seata以下默认配置为1s,当出现异常时会出现大量重试异常请求与日志。
高可用部署多台seata service实例时,高并发下还可能出现confirm/cancel同时被触发的问题(不能确定百分百由此引起,但是调整后测试数据40w订单未再现,原本一轮测试4000订单基本就可能会出现几个)
配置:
# 二阶段提交未完成状态全局事务重试提交线程间隔时间 默认1000,单位毫秒
server.recovery.committingRetryPeriod=20000
# 二阶段异步提交状态重试提交线程间隔时间 默认1000,单位毫秒
server.recovery.asynCommittingRetryPeriod=20000
# 二阶段回滚状态重试回滚线程间隔时间 默认1000,单位毫秒
server.recovery.rollbackingRetryPeriod=20000
# 超时状态检测重试线程间隔时间 默认1000,单位毫秒,检测出超时将全局事务置入回滚会话管理器
server.recovery.timeoutRetryPeriod=1500
2.seata高并发下小机率报错:“io.seata.common.exception.FrameworkException: TCC branch Register error, xid:”
配置:
server.enableParallelRequestHandle=false
说明:此问题会引起大量线程长时间被占用,导致并发能力下降,而且效果非常明显
关闭前下单接口请求:300ms ~ 1.5s, 100线程并发压测:46ms ~ 30s(有时60s)
关闭后下单接口请求:100ms ~ 500ms, 100线程并发压测:158ms ~ 2s
参考:https://github.com/apache/incubator-seata/issues/5520
进一步优化思考
从外部流量流入顺序一步步分析,云负载均衡->k8s控制节点nginx->k8s ingress->web nginx->service gateway->service trip 1.网络与转发性能问题 目前下单接口300线程并发能达到45~50qps左右,而查询接口能达250qps左右,空接口600qps/1500qps(higress)左右,所以网络与转发的性能问题不是瓶颈 2.JVM与cpu性能问题 当2台trip时就能达到40qps左右,三台的增涨太低,而且从Grafana显示的prometheus采集的pod信息来看,cpu基本在3核(上限4核)以下,并没有跑满。JVM的状态也良好,gc基本在20ms以内,对性能影响可以忽略不计 3.中间件与连接池 3.1.中间件性能从Grafana显示的prometheus采集的pod信息来看,负载都很低 3.2.数据库连接池druid配置为10-400,压测下基本在100-150,可能与cpu核心数有关,系统不会再分配更多了。druid监控面板能看到“获取连接时累计等待多少次”超过1W多,优化连接配置为20-400后降低到100多 3.3.看了下skyswalking分析,一个是出现了锁争抢的情况,20个产品30天操作碰撞机率还是不小,另一个是连接池的获取变慢了,出现Druid/Connection/getConnection 200ms(3.2的问题) 和Druid/Connection/close 84ms的请求,这些操作原本都是1ms甚至没有统计时间,可见连接池和数据库资源有点紧张,sql执行从之前的1~10ms以内变成了1~40ms 3.4.发现一个问题,从skywalking有时会看到业务完成后接口响应时间会有一个长长的拖尾,原来seata tcc confirm首次调用是同步的,try会提交本地事务后等待confirm执行,也就是说只要confirm没有异常,接口的返回时间是try+confirm的执行时间(confirm异常try返回成功,confirm进入重试),之前以为是异步的还在pay接口前加了400ms的等待时间,后面发现不加也不会导致pay接口异常,当时也没深想 ps:以上优化后2台trip下单100线程接口基本就能在42-50qps左右,变稳定了些,主要的问题点应该是数据库并发能力与业务代码问题,毕竟下单接口执行的sql有12(try)+14(confirm)个,本地事务有4个,虽然压测时从druid统计页面看sql最大执行时间基本在300ms以内,skywalking抽查sql基本在1-40ms左右,但是sql有点多可以优化缩减一下,数据库做个主从,查询走从库分担一下查询压力,另外数据库性能跑不满,最多只能压到百分60以内的cpu,qps在5000左右,单库本身配置应该也有优化空间。还有增加trip实例无法增加数据库压力这个问题还得看看,是哪个环节的配置对数据库做了限制或者保护,开放程度还是按需控制比较好 还漏了一个点,之前看skywalking其实锁冲突还是有不少的,只是觉得应该不是问题,但是没有确认过是不是锁限制了并发。应该在本地做个测试,同步测试数据,然后进行去掉锁和不去掉锁时的并发情况对比,根据结果就能确切判断问题在哪。
try等待confirm完成日志图
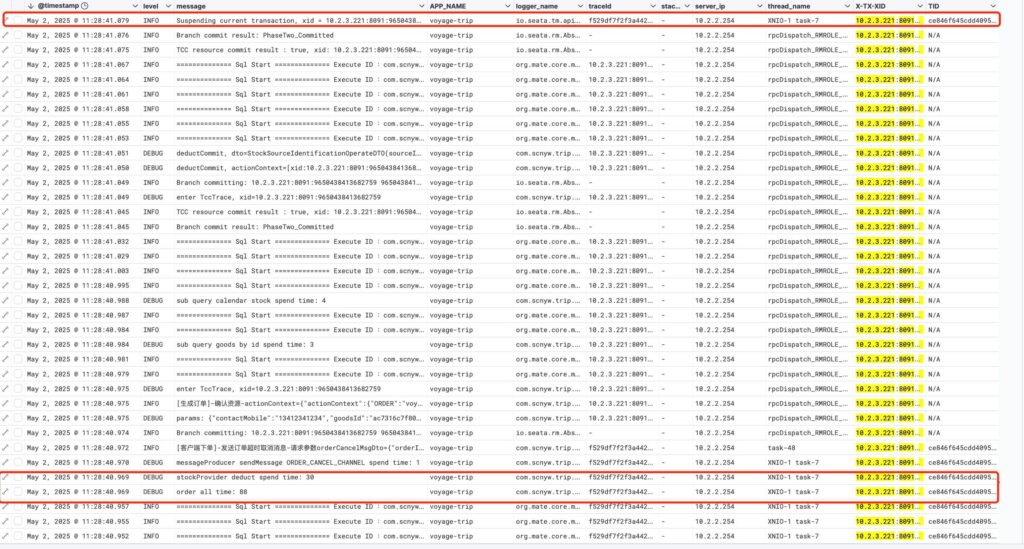
可以看到XNIO-1 task-7线程在confirm业务完成后才打印提交,整个完成时间与jmeter和skywalking完成时间一致
Related Posts

SSH转发的妙用(代理)
之前自己自建vpn,...


Lightroom后期照片调校
最近突然有一点心得,...